Table of Contents
Marginal Containers Covering Relevant Items (MACCORI) is a combinatorial optimization problem that is close but not the same as the knapsack problem. The unit of an inclusion or exclusion operation for a knapsack is done through a container, which has a cost and a set of weighted items. Given a set of containers, a MACCORI problem tries to find a subset of the given containers that maximizes the total score of the subset under the constraint that the total cost of the subset is less than a given limit. A total score of a subset of containers is defined to prefer relevant and non-redundant items, i.e., a resultant subset is expected to cover a wide-range of items with high weights. MACCORI can solve several real-world problems. For example, assuming that a container and its items represent sentence and its contents (e.g., n-grams, predicate-argument structures) respectively, a MACCORI problem can choose a smaller number of important sentences (extracts) in a given set of source documents [Okazaki04].
Suppose that we are given n containers each of which consists of m items with non-negative weights. An item with zero weight in a container stands for the situation where the container does not contain the item at all. We denote a set of source containers S as a matrix in which an element wi, j presents the weight of the item #j in the container #i.
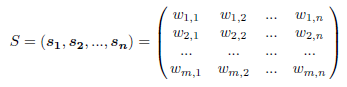
For example, in applications of sentence extraction with bag-of-words models, we may define wi, j to present the importance (e.g., TF*IDF) of the word #j in the source sentence #i
Our objective is to choose a container out of the source containers one by one while a certain constraint holds. Suppose that t containers are chosen from this operation. We denote the chosen containers as a vector of indices of the source containers.
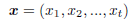
We call this as extraction vector hereafter. For example, the following vector represents that four containers s5, s9, s1, and s3 are extracted from the source containers in this order.
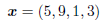
We determine the number of extracted containers t and the extraction vector x so that the total score of the extracted containers is maximized,
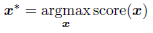
subject to the constraint,
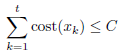
In these formulas, cost(xk) is a function to present the cost of choosing the container sxk, the constant parameter C specifies the maximim value of the total cost of the chosen containers, and the function score(x) assesses the total score of the chosen containers (to be explained). Note that, for simplicity, we omit the argument S for the functions, which have dependencies to the source containers. In applications of sentence extraction, we may let cost(xk) = 1 and C be the number of sentences to be extracted. Alternatively, we may define cost(xk) to present the number of letters in the sentence sxk and C to control the maximum number of letters in a summary.
We define the scoring function as the sum of the score at each step of choosing a container. In other words, a total score of extracted containers consists of the scores of the container extracted first, the container extracted after the first one, ..., the t-th container extracted after the (t-1)-th container.
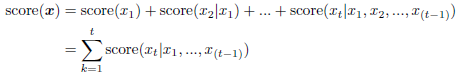
In this formula, score(xt | x1, ..., xt-1) presents the score of the container sxt after containers sx1, ..., sxt-1 are chosen. Note that the score of a container varies depending on the containers chosen previously (i.e., history). Finally, we define the scoring function at each step of choosing a container as follows.
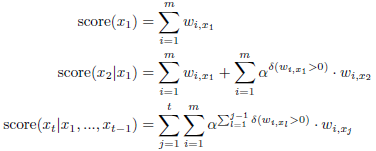
In these formulas, δ(condition) denotes a boolean function that yields 1 only if the condition is true, the [0, 1] parameter α is called duplicate item rate that controls the latitude of redundant items in extracted containers. Setting α to 0, the extraction process ignores the weights of duplicated items that are covered by the preceding containers. Setting the duplicate item rate α to 1, the extraction process does not discount the weights of duplicated items. Setting 0 < α < 1, the extraction process preferentially selects containers with novel items instead of redundant ones.
Given a set of source containers S and their costs, the MACCORI solver finds the optimal extraction vector x by using a beam search algorithm.
This is the BNF notation representing the data format of MACCORI problems.
<line> ::= <comment-line> | <container-line>
<comment-line> ::= ('#' | ';') <character>+ <br>
<container-line> ::= <container-id> <sep> <container-cost> (<sep> <weighted-item>)+ <br>
<container-id> ::= '"' <string> '"'
<container-cost ::= <numeric>
<weighted-item> ::= <item> ':' <weight>
<item> ::= '"' <string> '"'
<weight> ::= <numeric>
<sep> ::= '\t' | ' '
<br> ::= '\n'
For Windows environments, open the Visual Studio workspace (maccori.sln) and build it. If you are using a POSIX environment, follow the standard procedure to build the program with the configure script.
$ ./configure $ make $ make install
Here are command-line options that are important for solving MACCORI problems.
- -m, --method
- Specify the algorithm to assesses the degree of duplicated items included in resultant containers. The possible values are "maccori" (defaulted) and "mmr". Specifying the algorithm to "mmr" will emulate Maximal Marginal Relevance (MMR) proposed by Goldstein et al. [Goldstein00]
- -w, --beam-width=VALUE
- The maximum number of branches (child nodes) to which the solver expands from a node. The default value is 1. A larger value may find a better solution but increases the search space.
- -c, --beam-score=VALUE
- Do not expand a child node whose score is less than the specified value. The default value is 0 (no pruning).
- -f, --beam-adaptive[=TYPE]
- Control the beam width adaptively. This feature is disabled by default. If the type is "decline" or omitted, the solver determines the beam width for a child node as (n-k+1), where n is the beam width of the parent node and k is the precedence of the child node. If the type is "inverse", the solver assigns the beam width for a child node as (n/k).
- -r, --duplicate-rate
- Duplicate item rate. Specify a value between 0 to 1.
- -l, --max-cost
- The maximum cost that resultant containers can hold.
- -d, --max-depth
- The maximum depth of the search tree.
The complete list of command-line options is shown by -h (--help) option.
$ maccori -h
Marginal Containers Covering Relevant Items (MACCORI) version 1.0
Copyright (c) 2004-2008 by Naoaki Okazaki, all rights reserved.
USAGE: C:\home\okazaki\projects\maccori\Release\maccori.exe [options]
Read a MACCORI problem from stdin and output its solution to stdout.
I/O options:
-o, --output-format=FORMAT Specify the format of results, {plain,xml}
--encoding=ENCODING Specify the encoding for xml output [utf-8]
Search options:
-m, --method=METHOD Choose an optimization method, {maccori,mmr}
-w, --beam-width=VALUE Specify beam width [1]
-c, --beam-score=VALUE Prune containers whose scores are below VALUE [0]
-f, --beam-adaptive[=TYPE] Control the beam width adaptively {inverse,decline}
-r, --duplicate-rate=R Specify duplicate item rate [0]
Search constraints:
-l, --max-cost=VALUE Constrain the maximum cost of containers
-d, --max-depth=VALUE Constrain the maximum depth of search tree
Miscellaneous options:
--update=VALUE Update interval of search progress
--verbose Verbose mode
-h, --help Show the help message and exit
For more information about problem and solution formats, see the document.
This section describes a tutorial for making applications of sentence extraction for multi-document summarization using the MACCORI solver.
In this tutorial, we extract a small number of important sentences from a set of MEDLINE abstracts retrieved by the PubMed service with a specific query.
For example, after collecting MEDLINE abstracts referring to "beta2 adrenergic receptor" by using the PubMed service, we can generate an excerpt for the receptor by using the MACCORI solver.
We divide the summarization process into three steps: collecting source documents, generating a MACCORI problem, and solving the MACCORI problem.
The scripts for the tutorial are included in sample/summarization directory.
Firstly, we prepare source documents to be summarized.
The script medline.py retrieves MEDLINE abstracts that are relevant to the query specified in the command-line argument, by using the Web service provided by Entrez Programming Utilities.
This example downloads up to 100 MEDLINE abstracts that are relevant to beta2 adrenergic receptor and save them into source.xml.
$ cd sample/summarization/
$ python medline.py "beta2 adrenergic receptor" > source.xml
$ less source.xml
<?xml version="1.0"?>
<!DOCTYPE PubmedArticleSet PUBLIC "-//NLM//DTD PubMedArticle, 1st January 2008//
EN" "http://www.ncbi.nlm.nih.gov/entrez/query/DTD/pubmed_080101.dtd">
<PubmedArticleSet>
<PubmedArticle>
<MedlineCitation Owner="NLM" Status="Publisher">
<PMID>18219297</PMID>
<DateCreated>
<Year>2008</Year>
<Month>1</Month>
<Day>25</Day>
</DateCreated>
<Article PubModel="Print-Electronic">
<Journal>
<ISSN IssnType="Print">0895-7061</ISSN>
<JournalIssue CitedMedium="Print">
<PubDate>
<Year>2008</Year>
<Month>Jan</Month>
<Day>24</Day>
</PubDate>
</JournalIssue>
</Journal>
<ArticleTitle>beta1- and beta2-Adrenergic Receptor Gene Variation, b
eta-Blocker Use and Risk of Myocardial Infarction and Stroke.</ArticleTitle>
<Pagination>
<MedlinePgn/>
</Pagination>
<Abstract>
<AbstractText>The benefits of beta-blocker therapy may depend on
underlying genetic susceptibility. We investigated the interaction of common va
riation in beta1 and beta2 adrenergic receptor (AR) genes with beta-blocker use
on the risks of myocardial infarction (MI) and ischemic stroke in a case-control
study. Participants were treated pharmacologically for hypertension, aged 30-79
years, with incident MI (n = 659) or ischemic stroke (n = 279) between 1995 and
2004, and 2,249 matched controls. We observed an interaction of beta-blocker us
e with beta1-AR gene variation on MI risk (P value, 6 degrees of freedom: 0.01)
and ischemic stroke risk (P value, 6 degrees of freedom: 0.04). Compared with us
e of other antihypertensive medications, beta-blocker use was associated with hi
Then, we convert the source documents into a MACCORI problem. Although there are various ways of modeling source documents, this tutorial employs a simple strategy for sentence extraction:
- The unit of extraction is sentence.
- A sentence is represented by stemmed non-functional words.
- The weight of a content word is computed by TF*IDF, in which the term frequency (TF) is defined as the total occurrence of the word in the source documents.
- The weights of a sentence are normalized by the logarithm of the number of letters in the sentence.
- The cost of a sentence stands for the number of letters in the sentence.
The script medline_to_maccori.py implements the conversion from the source documents into a MACCORI problem, following the above strategy.
$ python medline_to_maccori.py < source.xml > maccori.txt $ less maccori.txt # 18219297:0 The benefits of beta-blocker therapy may depend on underlying genet ic susceptibility. "18219297:0" 86 "benefit":8.643856 "beta":51.995838 "blocker ":23.159541 "therapi":27.419512 "depend":21.303278 "underli":8.9518 36 "genet":20.603915 "suscept":11.509504 # 18219297:1 We investigated the interaction of common variation in beta1 and be ta2 adrenergic receptor (AR) genes with beta-blocker use on the risks of myocard ial infarction (MI) and ischemic stroke in a case-control study. "18219297:1" 212 "interact":17.740191 "common":9.764511 "variat" :7.513117 "beta1":29.193103 "beta2":22.740655 "adrenerg":17.75 3915 "receptor":24.923084 "ar":75.093927 "gene":27.963624 "beta":3 6.092113 "blocker":16.075840 "risk":18.487216 "myocardi":10.96 0416 "infarct":9.000000 "mi":13.058654 "ischem":11.705178 "stroke" :14.364519 "case":9.274198 "control":19.971540 "studi":19.691359 # 18219297:2 Participants were treated pharmacologically for hypertension, aged 30-79 years, with incident MI (n = 659) or ischemic stroke (n = 279) between 199 5 and 2004, and 2,249 matched controls. "18219297:2" 187 "particip":7.400875 "treat":8.700019 "pharmac olog":6.114200 "hypertens":15.762355 "ag":15.048185 "30":7.392715 "79":3.8 54814 "year":12.915739 "incid":2.569876 "mi":12.849381 "=":24.9 58038 "659":1.512608 "ischem":11.517596 "stroke":14.134320 "=":24.9 58038 "279":1.512608 "1995":1.512608 "2004":1.512608 "2,249":1.512608 "match":6.114200 "control":19.651485
Lines starting with '#' characters are comments and ignored by the MACCORI solver. These comment lines are to store associations between container (sentence) IDs and their contents. Other lines starts with a container ID (quotated string) and cost (numeric value). In the above example, the ID and cost of the first container are "18219297:0" and 86 respectively. A line continues with a list of pairs of items (quotated string) and weights (numeric value).
We can obtain a summary by solving the MACCORI problem with a parameter set. This tutorial determined the command-line options for the solver based on the following request for a summary:
- The total cost (number of letters) of extracted containers (sentences) must be less than 1000.
- The beam width for a search is no wider than 8.
- The duplicate information rate is 0.33.
- Use an adaptive control of the beam width for faster searching.
$ maccori -f -l 1000 -b 8 -r 0.33 < maccori.txt > result.txt
Marginal Containers Covering Relevant Items (MACCORI) version 1.0
Copyright (c) 2004-2008 by Naoaki Okazaki, all rights reserved.
Reading a problem (plain) from stdin... done.
[Problem and parameters]
Scale: 830 containers with 2936 items
Method: MACCORI
Constraint: length no longer than 1000
Parameter: redendant-coeff=0.33
Beam options: adaptive width (inverse); width=8; score=0
[Search progress]
Elapsed | Number of leaves | Sols. | Score | Depth
---------+-----------------------+-------+-------+-------
0:00 | 1.000e+000/5.120e+002 | 1 | 1509 | 3
0:00 | 1.000e+001/6.303e+002 | 2 | 1531 | 4
0:00 | 1.100e+001/9.027e+002 | 3 | 1879 | 5
0:00 | 3.800e+001/1.803e+003 | 4 | 1908 | 5
[Result]
$ cat result.txt
RESULT [depth=5; score=1908.42; length=997;]
1: "17714090:3",104
2: "17680985:5",422
3: "17975187:6",322
4: "17670382:8",129
5: "17382299:4",20
This result shows that the MACCORI solver chose sentences "17714090:3", "17680985:5", "17975187:6", "17670382:8", "17382299:4". Looking up sentences with these IDs will yield a summary.
[Okazaki04] “TISS: An Integrated Summarization System for TSC-3”. Proceedings of the Fourth NTCIR Workshop on Research in Information Access Technologies Information Retrieval, Question Answering and Summarization. 2004.
[Goldstein00] “Multi-document summarization by sentence extraction”. NAACL-ANLP 2000 Workshop on Automatic summarization. 40-48. 2000.